Datos No Estructurados
Ejemplo: Tablas en SharePoint Lists, datos en Excel Online.
Uso ideal: Automatización con Power Automate + IA (ej: clasificar tickets de soporte).
Script útil:
powershell
# Extraer datos de una lista SharePoint para análisis Connect-PnPOnline -Url "https://tuempresa.sharepoint.com/sites/datos" Get-PnPListItem -List "Clientes" | Select-Object -Property Field1, Field2
Datos No Estructurados
Ejemplo: Documentos en OneDrive, emails en Exchange.
Cómo explotarlos: Usar Microsoft Syntex (IA para clasificación automática).
Metadatos Críticos
Ejemplo: Propiedades de archivos en SharePoint (autor, ubicación).
Herramienta: PowerShell para auditoría:
powershell
Get-PnPFile -Url "/sites/datos/Documento.docx" -AsListItem | Select-Object -Property *
Datos Sintéticos:
¿Qué son los datos sintéticos? Son conjuntos de datos fabricados artificialmente que imitan las características y distribuciones de los datos reales, sin contener información personal o sensible. Fuente: https://datos.gob.es
¿Por qué necesitamos datos sintéticos?
Escasez de datos de valor
Problemas para acceder a datos de calidad
Datasets reales presentan sesgos o están desequilibrados
Aumento de las regulaciones sobre privacidad de datos
Ante la dificultad de acceder a datos de calidad para entrenar modelos IA, la generación de datos sintéticos se ha convertido en una herramienta clave para mejorar la eficiencia y efectividad de dichos modelos.
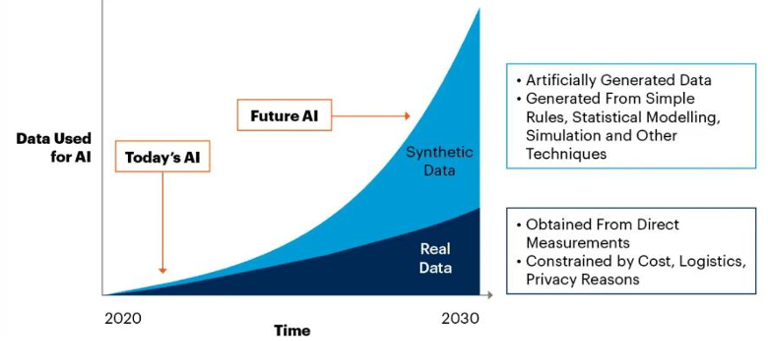
Ventajas:
Recreación de eventos no habituales.
Enriquecimiento de conjuntos de datos pequeños.
Generación de clases con baja representación.
Alternativa a las técnicas de anonimización.
Permite colaboración entre proveedores de datos de distintos países con distintas regulaciones.
Reduce el riesgo de filtraciones de datos personales durante el proceso de desarrollo.
Reducción de costes para obtener datos.
Reducción de costes asociados a mantener la privacidad de los datos y potenciales problemas legales.
Generación a demanda, que impacta en menores costes de almacenamiento.
Desventajas:
Pérdida de realismo por carencia de complejidad y variabilidad.
Riesgo de aparición o amplificación de sesgos, si se dan en los datos originales.
Falta de validación.
Limitaciones en aplicaciones críticas, como medicina, banca o transporte.
Complejidad técnica de las herramientas para generar datos sintéticos de alta calidad.
Dependencia del conjunto de datos original, p.ej. problemas de generalización.
Aceptación limitada en algunos sectores.
Servicios
Consultoría y formación en inteligencia artificial personalizada.
Innovación
Automatización
hola@intergroia.com
+34 602 644 914
© 2025. IntegroIA. All rights reserved.